ROST is a framework for semantic modeling of streaming sensor data, such as audio, video and depth. ROST works in realtime, and is suitable for use in a robotics context. Given a sensor data stream, ROST outputs a stream of low dimensional descriptors that are semantically relevant, and can be used for high level tasks such as summarization, surprise detection, and autonomous exploration.
Demonstrations
A simple example
ROST can be used to automatically build unsupervised models of different objects in a scene, which can then be used to detect and describe high level scene changes. In the example below, we see that ROST is able to represent the two different objects using two different topics, and then correctly recognize the scene with both the objects present at the same time as being surprising. Note that this is done in a completely unsupervised manner, with no prior information about the scene.
Topic modeling of video from an indoor lab environment
The following video shows ROST being used to describe an indoor lab enviroment in realtime. The colors of the visual features correspond to the semantic topic labels that are automatically assigned. We see that over time ROST is able to consistently label different parts of the scene with appropriate topics. These topics are then being used to build an extremum summary, which contains images corresponding to different parts of the room.
Topic modeling of video from an underwater environment
ROST works well with unstructured environments. The following video shows ROST being used to summarize a video collected by an underwater robot. We see that the system is able to succesfully differentiate between live corals and rocks, as is shown in the resulting summary.
Exploring Underwater Environments with Topic Modeling Based Curiosity
The following video illustrates our work on vision-based information-seeking as applied in the context of underwater robotics. The video shows an Aqua2 amphibious hexapod swimming through the ocean searching for visually interesting context. The search and modeling of novel content, that is, curiosity, is a fundamental characteristics of most intelligent systems, and is one of the universal attributes of intelligent species. In the robotics context, we would like robots to plan exploratory path through the environment, which would allows it to efficiently learn about new and different scene constructs such as objects and terrains. The video below demonstrates an implementation of such a system.
The underwater robot is equipped with a wide angle camera in the front, and the captured images are processed by ROST, which extracts low level visual features in these images and gives them topic labels, representative of high level scene constructs such as corals, plants, diver and rocks. Now, given the description of the current scene in topic space, the robot then identifies the part of the scene with most novelty in topic space (shown with a red circle in the video). We use a winner-take-all strategy to determine this area of attention with maximum information gain, and then navigate the robot laterally in the direction of this point.
The authors would like to thank Ioannis Rekleitis for his underwater videography.
Topic modeling of ambient sounds for location recognition
Using ROST on ambient sounds that were recorded as we traverse an environment results in topics corresponding to different locations and other sound producing sources. In the example below we see that we have topics which stay stable while we are in the same region, and change when we move from one region to the other. We see that the peak topic changes as we move from lab to stairs, from stairs to lobby, from lobby to street, and so on. Also as we return to the lobby, the topic model converges to the same topic that was used to reprsent the lobby previously. Plot on the top right of the video shows the distribution of MFCC words, and the plot on the bottom right shows the topic distribution of the current time step. Note that the example below only uses audio for building the topic model.
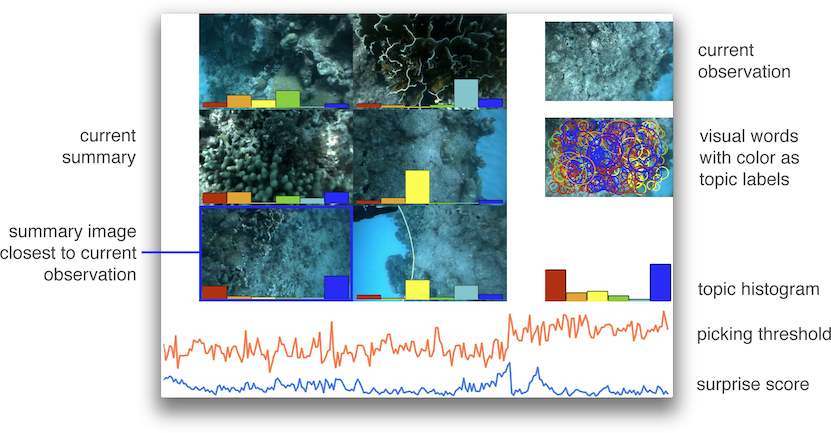
What am I seeing?
Current Observation:
last image observation made by the robot.
Visual words:
visual words are extracted from the current observations, and are given a topic label. Size of the circle corresponds to the size of the visual feature, and the color corresponds to the topic label.
Topic histogram:
distribution of topic labels in the current observation.
Current summary:
set of images in the current summary along with their corresponding topic histogram. These topic histograms are updated in each iteration, in the light of new observed data.
Closest summary image:
topic distribution of the incoming image is compared with the topic distribution of all the summary images; the closest one (with the smallest KL divergence) is marked with a blue boundary around it.
Surprise score:
shown with blue color in the plot, is the distance betweeb the topic distribution of the current observation and the closest image in the summary.
Picking threshold:
shown with orange color in the plot, is the threshold surprise score for adding the current observation to the summary. It is computed using the images in the current summary.
Relevant Publications
Exploring Underwater Environments with Curiosity
Yogesh Girdhar, and Gregory Dudek
IEEE Conference on Computer and Robot Vision (CRV2014).
Curiosity Based Exploration for Learning Terrain Models
Yogesh Girdhar, David Whitney, and Gregory Dudek
IEEE International Conference on Robotics and Automation (ICRA 2014).
Unsupervised Environment Recognition and Modeling using Sound Sensing
Arnold Kalmbach, Yogesh Girdhar, and Gregory Dudek
IEEE International Conference on Robotics and Automation (ICRA 2013), Karlsruhe, Germany.
Realtime Online Spatiotemporal Topics for Navigation Summaries
Yogesh Girdhar, Raheem Adam, and Gregory Dudek
7th Annual Machine Learning Symposium, New York, New York.
[Spotlight Presentation 3rd Prize]
Efficient On-line Data Summarization using Extremum Summaries
Yogesh Girdhar and Gregory Dudek
IEEE International Conference on Robotics and Automation (ICRA 2012), St. Paul, USA.
ONSUM: A System for Generating Online Navigation Summaries
Yogesh Girdhar and Gregory Dudek
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2010)
Code
Code used to generate the demonstrations below is available HERE. The code runs on Robot Operating System.
More recently, I have been working on command line version of these tools. These are available HERE.
Yogesh Girdhar
Last modified: Mon Nov 24 11:37:52 EST 2014