Performance
In order to demonstrate the effectiveness of parallel programming, we must show that the elapsed time (wall clock time) is lower for the parallel versions of our program. In general it will not be possible to get a 100% performance increase per node, unless the problem is coarse grained, and requires little synchronization.
Our tests were performed on a cluster of 16 dual PIII 700MHz with 384MB of RAM. We ran the program to calculate the number of primes between 0 and 10 000 000. Here are the times for the three versions of our program developed so far:
Serial Implementation on 1 node : 6:29.28 seconds.
Multi-threaded Implementation on 1 node : 3:24.24 seconds.
Distributed (and multi-threaded) Implementation on 16 nodes : 11.05 seconds.
These results show that we are getting a linear increase in performance per processor (32x speed improvement over serial version).
Load Balancing
One of the biggest problems encountered when programming a multicomputer is that of keeping each computer, and each processor in SMP computers, as busy as possible. We would like to avoid having several machines sit idle while waiting for the results of another computation being performed on a separate machine or processor. This delicate art is known as load balancing.
While a complete discussion of load balancing is beyond the scope of this tutorial, we can examine a few properties of the specific problem we are solving to try to learn how to improve our performance. The single function which performs the bulk of the computation in our example is the is_prime() function. Due to its nature, its time is proportional to the size of the input number. Consider how we are breaking up the problem in our threaded implementation when using 2 threads: we send the half of the numbers to one thread, and the other half of the numbers to the other thread. This is inherently unbalanced because we divide the numbers sequentially. The thread with the lower half of the numbers will complete much earlier than the thread with the upper half of the numbers, and hence one processor will sit idle. There are at least two approaches to fixing this particular problem: when dividing the range of numbers, we can send every other number to each thread, or we can simply use more threads which will break up the problem into smaller chunks, and rely more on the kernel thread scheduler to balance the load. This will only work to a certain point where the time spent scheduling will exceed the gain of splitting up the problem. An example of the performance increase of using an increasing number of threads can be seen in Figure 1. Note how the performance starts to stabilize around 25 threads. This is the point of diminishing returns for the particular problem size in this example.
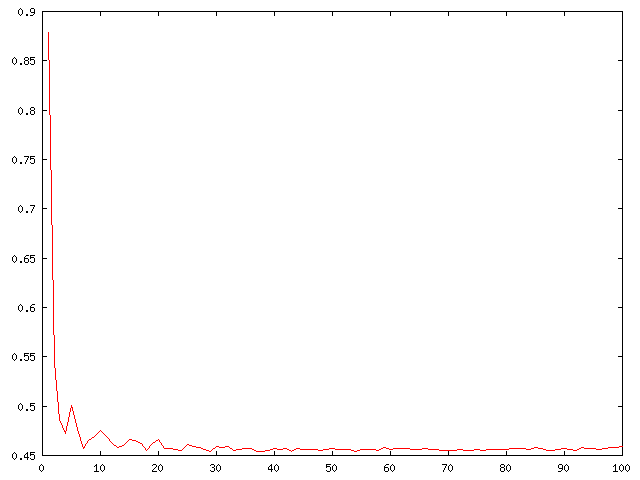
A plot of the performance in seconds (y axis) versus the number of threads used (x axis). In this example, the times were averaged over 10 iterations, and the goal was to find the number of primes between 0 and 10 000. The machine used for testing was a dual PIII 700MHz running kernel 2.2.16-smp.
Figure 1. Thread Performance
There is a much more robust approach to load balancing which we used for sending jobs to machines in the distributed implementation: send out smaller chunks of work to each machine, and only send them new work when they have completed their initial work. We still need to worry a bit about the size of the chunks we send out (controlled by the STEP_SIZE variable in our implementation), or else we will be increasing our network traffic without increasing our throughput. A similar approach could have been used to balance the threads, but was not used for the sake of clarity.