Generating Convincing Simulation of Internalized Voices for Human-avatar Interaction
Abstract
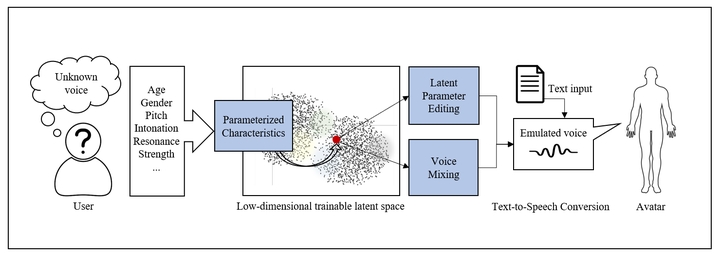
Speech synthesis has been developed to mimic the identity of a reference speaker and generate virtual speech in that particular voice. In the medical domain, this technology has recently been utilized to simulate auditory hallucinations in the treatment of schizophrenic patients, for which there are often limited resources available to recreate a convincing simulation. In this thesis, we develop a voice modelling interface paradigm that generates a representation of the voice that lies solely in the individual’s head. We first propose three exploration strategies to search for a voice sample that closely matches the user’s target voice, and then optimize the output voice with two techniques: latent parameter editing and voice mixing. Through these techniques, we quantify a set of salient vocal characteristics and adjust them, or create new vocal avatars from a low-dimensional voice latent space. To evaluate our approaches and output voices, we conduct two user experiments and a cluster analysis based on multidimensional scaling. We investigate both the performance and usability of our three exploration strategies and two manipulation techniques. The main results demonstrate that our approaches not only achieve superior performance compared to existing voice morphing interfaces but are also capable of finding a convincing match of any human voice imagined by users. The voices generated and customized through our system can be easily transformed into new speech with an arbitrary text input. This way, we aim to allow the general public to depict their internalized voices and improve the quality of the auditory modality in avatar creation or voice-based applications.
Hyejin Lee
Full-Stack Developer and Researcher
My interests include full-stack development, machine learning, human-computer interaction, AR and VR.