

About
I am an M.Sc. student at McGill University under the supervision of Professor Tal Arbel at the Probabilistic Vision Group (PVG). My current research focuses on developing deep-learning models based on GANs and diffusion models leveraging medical images.
You can find my complete CV here.
Research Interests
- Generative Adversarial Networks
- Diffusion Models
- Representational learning
- Computer vision
Education
-
Bachelor of Science
Sharif University of Technology, Tehran, Iran
Experience
-

Research Intern
EPFL (VITA Lab), Switzerland
-

Senior Software Engineer & Data Scientist
CafeBazaar (Divar), Iran
-

Software Engineer
Yektanet, Iran
Publications & Conferences
MIDL DeCoDEx: Confounder Detector Guidance for Improved Diffusion-based Counterfactual Explanations
The paper introduces DeCoDEx, a new framework designed to enhance explainability in deep learning classifiers by addressing the issue of models focusing on dominant confounders rather than causal markers. This is achieved through a pre-trained binary artifact detector that guides a diffusion-based counterfactual image generator during inference. Tested on the CheXpert dataset, DeCoDEx effectively alters causal pathology markers relevant to Pleural Effusion while handling visual artifacts. The approach also boosts classifier performance across underrepresented groups, significantly improving generalization. The framework's code is publicly available for further exploration and use.
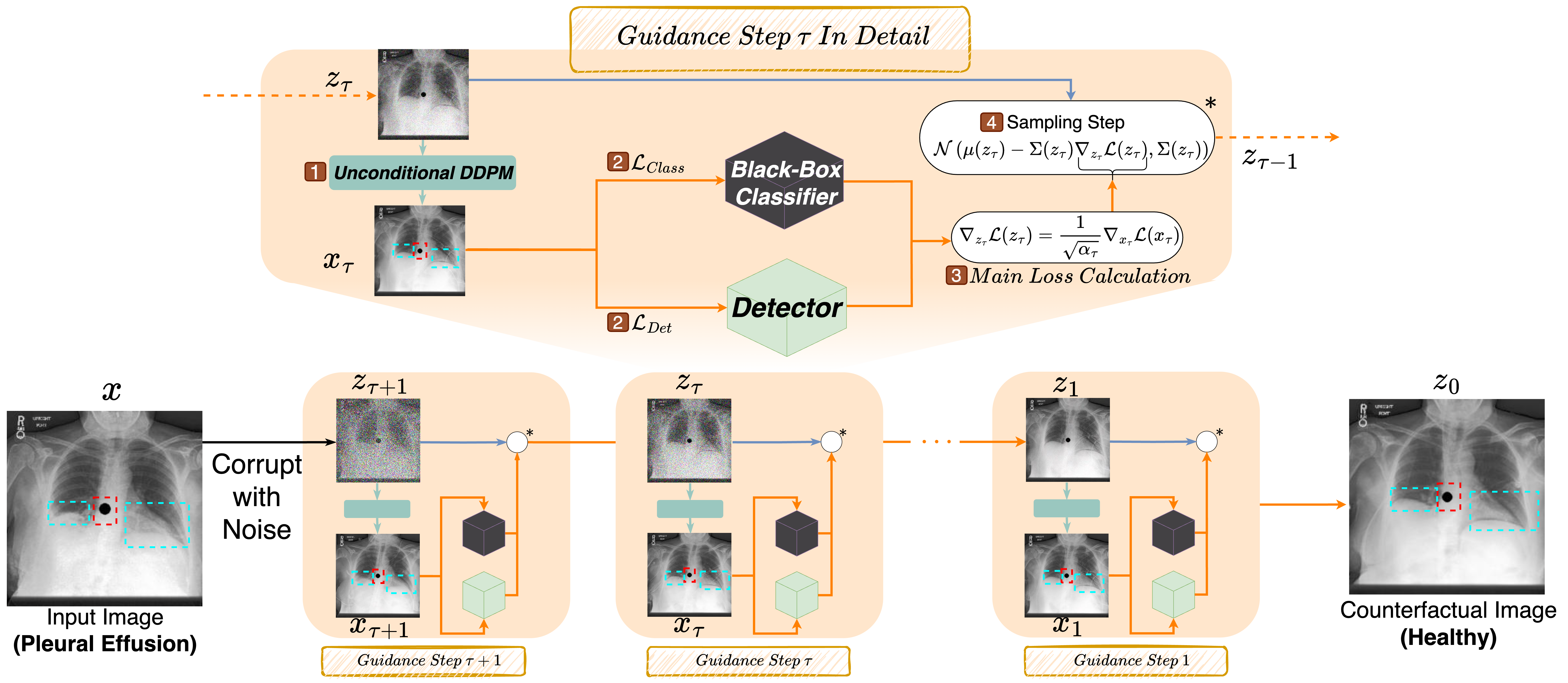
MICCAI Worksop Debiasing Counterfactuals in the Presence of Spurious Correlations
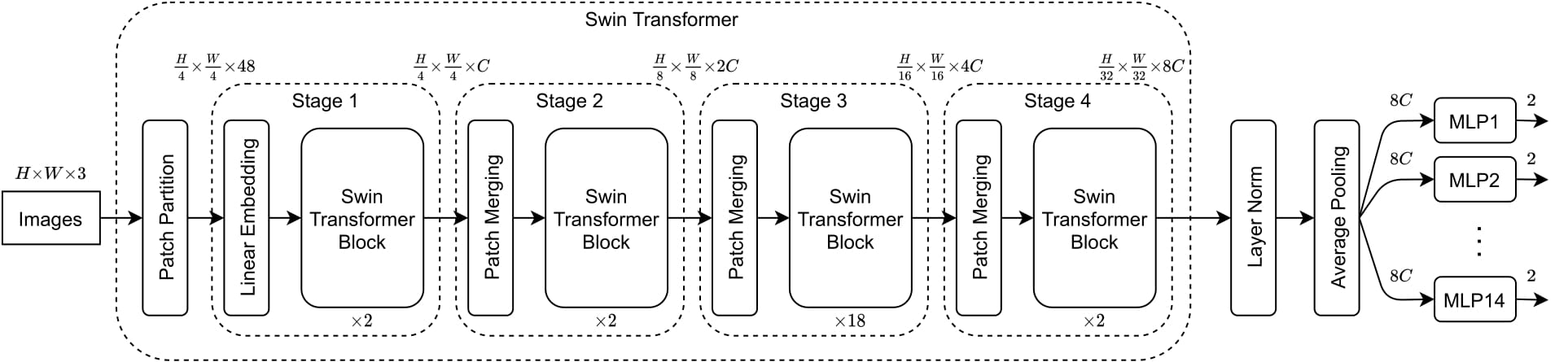
This paper introduces a multi-label classification model using a Swin Transformer for analyzing chest X-rays, combined with a multi-layer perceptron (MLP) head architecture. Extensive testing on the "Chest X-ray14" dataset, containing over 100,000 images, shows that a 3-layer MLP head configuration achieves state-of-the-art performance with an average AUC score of 0.810.
ICCV Workshop Towards Human Pose Prediction using the Encoder-Decoder LSTM (ICCV2021 Workshop)
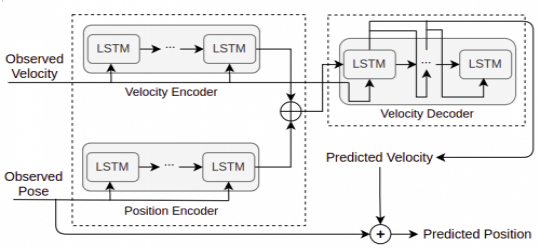
The ICCV workshop paper presents a Recurrent Autoencoder Model for human pose prediction, a fine-grained task focusing on predicting future human keypoints from past frames, with applications in areas such as autonomous driving. Tested in Stanford University's "Social Motion Forecasting" challenge, the model demonstrates its effectiveness by outperforming existing baselines by over 20% in evaluation metrics.
2021, made with in pure Bootstrap 4, inspired by Academic Template for Hugo